※ 작성자가 작성한 내용이 일부 틀릴 수도 있음 주의
※ 이 글에서 사용하는 프로그램 모두 오픈 소스를 이용했기 때문에 직접 코드를 올리지 않음
※ 직접 하면서 알게된 것을 모두 써서 사족이 많음
RVC (Retrieval-based-Voice-Conversion)
뭐 AI 라는 것이 다 그렇지만, 결국 방식의 차이가 있을뿐,
효율성을 높이는 것이 그 목적이며, 그렇게 매번 새로운 기술이 나오기 마련이다.
그래서 23년 4월에 나온 것으로 보이는 이 RVC를 이용해서
저번 글에서 모았던 목소리 데이터를 가지고 학습을 시킬 것이다.
참고로 SCE-TTS에서 제시한 방법은 학습에 대략 2~3시간 정도로 예상되며,
RVC는 실제로 약 3~40분(데이터 양에 비례) 정도가 걸렸던 것을 생각하면
RVC가 확실히 빠르긴 했다고 생각한다.
다만! 성능에 데이터량의 영향이 분명히 존재하며, RVC 또한 많은 양의 데이터를 이용하면
오래걸릴 수도 있으니, 반드시 "RVC가 더 빠르고 좋다!" 라고 보기는 어렵다는 점을 기억해야 한다.
개인적으로, RVC가 최소로 요구하는 데이터가 적다 정도로 생각하는 편이다. (확실 X)
데이터를 모으는 방법은 전 글을 확인하자 (또다른 방법은 추후에 글로 작성 예정)
https://syerco0.com/47
디스코드 봇 개발 일지 2023-07-03 - TTS 봇 - 목소리 데이터 모으기 (1)
※ 작성자가 작성한 내용이 일부 틀릴 수도 있음 주의 ※ 이 글에서 사용하는 프로그램 모두 오픈 소스를 이용했기 때문에 직접 코드를 올리지 않음 ※ 직접 하면서 알게된 것을 모두 써서 사족
syerco0.com
목소리 학습을 해보자
https://k66google.tistory.com/838
AI음성기술 RVC와 VC Client라는 보이스체인저를 사용해보았다.
작년부터 계속 그래픽카드를 활용한 AI 기술들이 나오고 있다. AI로 그림을 그리지 않나, AI가 대답하는 채팅봇이 나오지 않나, 심지어 이젠 AI가 목소리까지 만든다. 그야말로 온 세상이 AI 천국이
k66google.tistory.com
RVC를 이용한 학습 및 테스트에 대해서는 위의 글을 참고했다.
이 블로그만을 참고해서 할 수 있으며, 이 밑은 개인 기록, 요약을 위해 적은 것임을 참고하길 바란다.
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/README.ko.md
위의 링크가 RVC를 이용한 학습 프로그램 오픈 소스를 포함하고 있다.
설명이 이래저래 많지만, 내려보면 hugging face를 통한 다운로드 링크가 있다.
(https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main)
lj1995/VoiceConversionWebUI at main
huggingface.co
여기에서 RVC-beta.7z를 다운을 받고 압축을 풀면 된다.
압축을 푼 후, go-web.bat을 실행하면 웹UI를 통해 학습 프로그램을 돌릴 수 있다.
참고로 권한같은 거 허용하라는 게 뜨면 허용해줘야 된다.
그러면 localhost:(포트) 형태로 주소가 떠있고, 프로그램을 돌릴 준비가 된다.
RVC-beta-v2-0618
이 밑으로의 그림과 설명은 RVC-beta-v2-0618을 기준으로 되어있어
이후의 버전에서는 또 다를 수도 있다.
위에서부터 하나씩 봐보자.

일단은 나머지는 두고, 지금 하려는 것은 학습이니까 'Train'을 선택해주자.
그러면 위와 같이 나타난다.
Step 1부터 볼건데,
'Enter the experiment name' : 학습된 모델은 .pth 확장자로 결과물이 나올 것인데, 그 이름을 정하는 것.
'Target sample rate' : 음성 파일에는 sample rate라는 것이 있는데, 잘 모른다면 그냥 '40k'로 하면 된다.
후술할 Version이 v2여도 그냥 '40k'로 하면 웬만해서 큰 문제가 없다.
'Wheter the model has pitch...' : 피치 가이던스를 포함할 것인지. 노래 부르게 시키려면 필수, 그냥 말은 선택인데
안 해서 나쁠거는 없다. 그냥 'true'로 하자.
'Version' : 솔직히 사용 설명서 안 읽어서 정확히 모르겠다. 그냥 원하는대로 하자.
'Number of CPU...' : 학습동안 사용할 CPU(코어) 개수인데, 기본은 아마 현재 프로세스의 코어 개수를
자동으로 지정하는 것 같다. CPU의 코어 개수를 넘지 않게 원하는대로 지정하자. 그냥 놔둬도 된다.
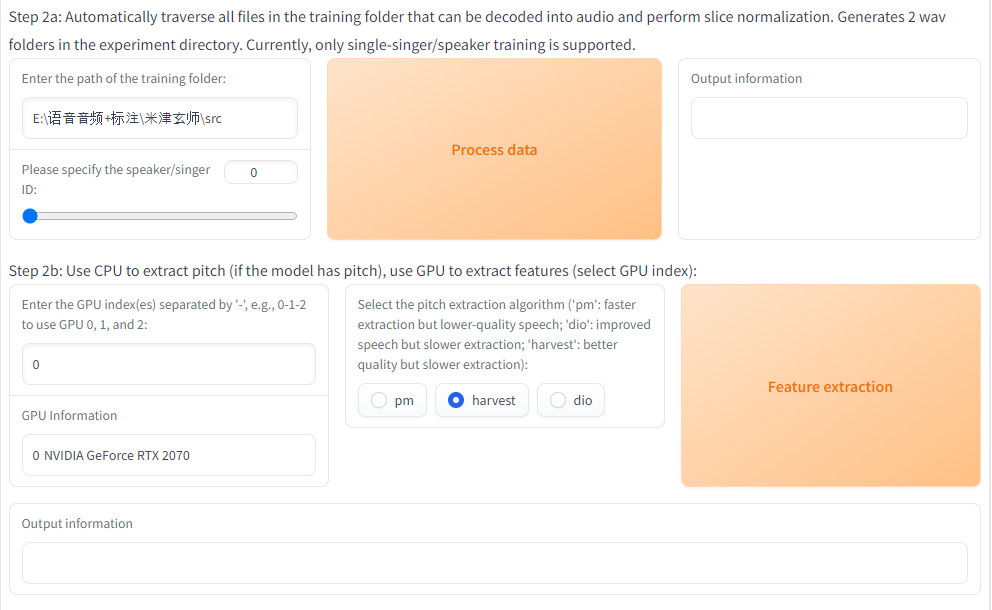
Step 2에서는 그냥 맨 왼쪽 위만 봐도 된다.
'Enter the path...' : 학습시킬 음성 데이터를 담은 폴더의 위치를 지정해주면 된다. 여기서 주의 사항이 있다.
경로에 있는 폴더들의 이름에 공백이 있어서는 안된다.
대충 말하자면, 명령어가 자동으로 들어갈 때, 공백을 기준으로 다른 argument로 인식해서
에러를 띄우고 더 이상 돌아가지 않는다.
이것만 조심하면 나머지는 바꿔줄 필요가 없다.
자동으로 들어갈 부분은 알아서 들어간다.

여기도 조절이야 할 수 있지만, 결국 학습 진행중에 저장/캐싱 등과 관련된 것들은
굳이 바꿀 필요가 없으니 1가지만 보면 된다.
위쪽 두 번째 'total training epochs'를 한 20~40 정도로 하면 될 것이다.
학습 반복 횟수인데, 굳이 엄청 많이 해줄 필요도 없고, 개인적으로 30(참고한 블로그에서 추천했음)이
적당한 것 같기는 하다.
한 30분 분량의 데이터로 45분 정도였나 걸린다.
보통 반복 횟수와 학습 시간이 비례하니, 원하는대로 정하면 된다.
다 정하고 나면 'One-click training'을 누르고 완료될 때까지 기다려보자.
에러! 에러!
Traceback (most recent call last):
File "multiprocessing\process.py", line 315, in _bootstrap
File "multiprocessing\process.py", line 108, in run
File "C:\Users\USER\Desktop\목소리AI\RVC-beta-v2-0618\train_nsf_sim_cache_sid_load_pretrain.py", line 108, in run
train_dataset = TextAudioLoaderMultiNSFsid(hps.data.training_files, hps.data)
File "C:\Users\USER\Desktop\목소리AI\RVC-beta-v2-0618\train\data_utils.py", line 18, in __init__
self.audiopaths_and_text = load_filepaths_and_text(audiopaths_and_text)
File "C:\Users\USER\Desktop\목소리AI\RVC-beta-v2-0618\train\utils.py", line 275, in load_filepaths_and_text
filepaths_and_text = [line.strip().split(split) for line in f]
File "C:\Users\USER\Desktop\목소리AI\RVC-beta-v2-0618\train\utils.py", line 275, in <listcomp>
filepaths_and_text = [line.strip().split(split) for line in f]
File "codecs.py", line 322, in decode
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb8 in position 26: invalid start byte
나의 경우 이런게 뜬다. 이거 말고도 하나 더 있는데, 일단은 이거부터 해결하자.
간단히 말하자면, 인코딩 관련 문제다.
RVC-beta-v2-0618\train\utils.py
이 파일의 275번째 줄에서 utf-8로 인코딩된 파일을 열려고 했는데,
음성 파일이 utf-8로 인코딩 된 것이 아니었던? 그런 것에 의한 에러인 것으로 추정된다.
이 파일의 274번줄
with open(filename, encoding="utf-8") as f:
여기서 "utf-8" 대신 "euc-kr"을 넣어주자.
그러면 해결된다.
또다른 에러?
사실 학습이 완료될 때 또다른 에러가 발생했다.
대충 "No such file or directory" 관련 에러인데,
대충 보아하니 로그 관련이라 필수는 아니라서 상관없을 것이다.
어쨌든 에러 메시지가 떠도 'weights' 폴더에 .pth 파일이 생겼을 것이다.
이것이 학습된 모델이다.
이 모델을 테스트하는 것은 다음에 작성하도록 하겠다.
벌써 내용이 길어졌네
여담
그림 그리는 것을 좋아하는데
조만간 다시 공부해보려고 한다.
군대에서 책 사서 조금만 독학하다가
복학하고 바빠서 못했는데
시간이 되면 '기록'으로서 이 블로그를 이용을 해야겠다.
언제 처음 올리고 계속 연습하게 될라나
잘 그릴 수 있으면 좋겠다.
'개발일지 > 디스코드 봇' 카테고리의 다른 글
| 디스코드 봇 개발 일지(아님) 2023-07-19 - 학습한 AI 모델한테 노래 부르게 하기 (0) | 2023.07.19 |
|---|---|
| 디스코드 봇 개발 일지 2023-07-12 - TTS 봇 - 갑자기 깨달음 (계획 변경) (0) | 2023.07.12 |
| 디스코드 봇 개발 일지 2023-07-03 - TTS 봇 - 목소리 데이터 모으기 (1) (0) | 2023.07.03 |
| 디스코드 봇 개발 일지 2023-06-26 - TTS (Text to Speech) 봇 (1) - 아이디어 구상 (0) | 2023.06.26 |
| 디스코드 봇 개발 일지 2023-03-03 - OpenAI 업데이트 및 모델(GPT3.5-turbo) 교체 (16) | 2023.03.04 |


